(Copied from old typewritten and handwritten notes, circa 1983, formatted to HTML, with minor editorial changes and typo fixing.)
See also pages with detailed implementation notes on MBC for the Magellan project and Galaxy Project.
Monobyte Code (MBC) resembles machine code (m-code) except for being more sophisticated. It can be thought of as a machine code for a pseudo machine implemented in regular machine code. Despite its potential as a machine-independent primitie lanugae, it is not for this use that MBC is intended. Originally, MBC was a technique of saving space in coding the Magellan Project. With the epxerience gained on that project, we now consider MBC to be a language optimized for interpretation of the NCS language. Basically, in the systems we evnistion, a compiler would read NCS and produce MBC object code, then an interpreter would execute the Monobyte Code. In this way, MBC is comparable to "p-code" of Pascal language systems [of the 1970s - early 1980s].
As a major component of an NCS system, MBC must cooperate with threaded code techniques. A routine written in MBC may call subroutines that are again written in MBC. Subroutines may also be written in machine code. The ultimate most primitive subroutines of course must be written in machine code.
Each Monobyte Code has associated with it a subroutine which performs an action. The interpreter, call the Monobyte Needle (MBN) (threaded code, needle, get it?) sequentially reads MBCs and for each one calls its associated subroutine. The Monobyte Needle really doesn't understand the MB language aside from certain special termination and access codes; it only knows how to look up subroutine locations and call subroutines.
The purpose of threaded code structuring is to allow the user to define new words in a language as a sequence of subroutine calls to previously defined words. One use-defined word may in turn be used within another usre-defined word. Re-enterant words are definable.
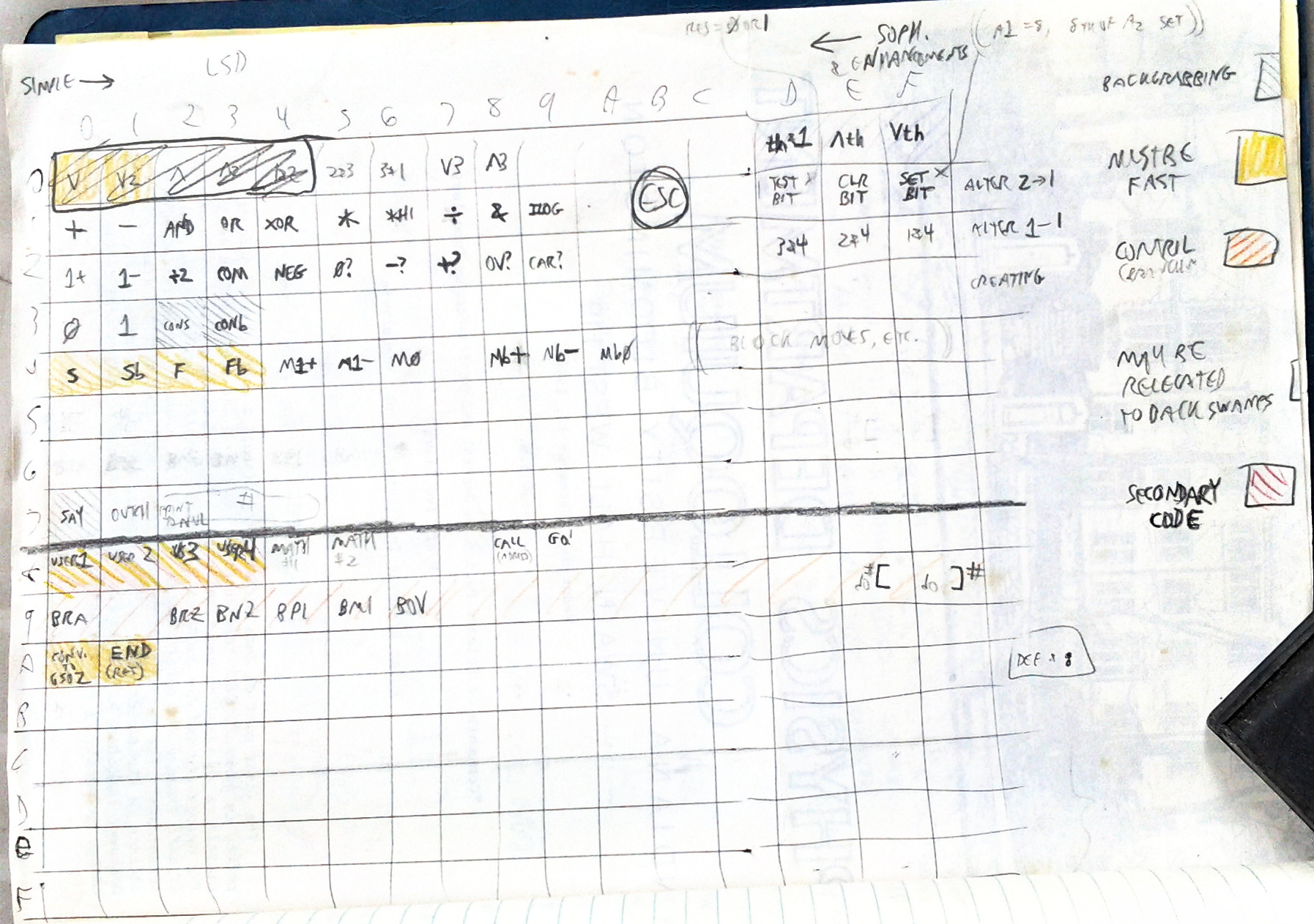
If new words are to be compiled to MBC, then means must be provided for extending the MBC language. The reason this pseudo-machine language is calle "Mono-Byte" is beacuse each operation uses one byte of code. That would allow only 256 possible operations. IN a system such as Galaxy or even the defunct Magellan, the operating system by itself uses more than half of these codes for primitive NCS operations, I/O modules, and more. To allow more usable codes, special access codes followed by a second byte specifying the operation opoen up romm for thousands of codes. This is similar to teh Z80's opcodes 0xDD and 0xFD for operations using its IX and IY registers. Several access codes allow sophisticated systems of dictionaries capable of compiling code according to context. Magellan had only one access code allowing a maximum of 511 possible codes.
Besides simple codes that manipulate data, we have codes for branching adn looping to alter the flow of control and make decisions. Relative addresssing only is used to that modules written in NCS may be relocatable.
The interpreter we call the Monobyte Needle has a very simple job. It must sequentially read bytes, which will be MBCs, and for each one it must determine an addresss of a subroutine to be called. How this is done will be described below. Finally, knowing that address, it calls that subroutine. These subroutines will always be assumed to be written in machine code. How simple! Perhaps a check for an "END" code could be included in MBN, though it could be implemented as a subroutine which manipulates the return stack. It depends on how one wants to optimize the system.
The MBN is responsiuble for keepoing a pointer to the curently active MBC, something like a Program Counter, but to avoid confusion with the machine's PC we will call this the MBPC. When MBN calls a subroutine, it should save the MBPC on the return stack, along with the machine's PC, because that subroutine may turn out to be implemented in MBC.
But no, actually that may be foolish, for the subroutine may be pure m-code, and we would have done unnecessary stack work. Only if the called subroutine is written in MBC should the MBPC be saved. Given how a subroutine, which is assumed to be written in m-code, invokes the MBN to read the following MBC, it makes sense that the best time to save the MBPC is wehn MBN is invoked, before anything else happens.
Just how is MBN invoked? How can a subroutine be hybrid, that is, part MBC and part m-code? These are problems of conversion. MBN is invoked by a jump-to-subroutine, followed by the MBC sequence. A special MBC tells the interpreter that MBC is done, to continue execution with the following regular m-code. There is also an MBC which means return-from-subroutine. These are best explained as examples. In these examples, m-code operations are written in CAPITAL letters, while Monobyte codes are underlined.
A plain simple m-code modules has a subroutine like this:
An example of using (almost) only MBC, but reverting to m-code to return:
Slightly more efficient is returning directly from the MBC portion:
A made-up example of a hybrid subroutine:
If one is implementing an MBC system on a Z80, a restart code (one byte) would be very useful in place of the JSR MBN operation (3 bytes). Conversion from m-code to MBC, or back, would take only one byte.
This is what happens when the latter hybrid subroutine is called: Prior to any execution of code, the machine program counter (mPC) is saved on the return stack. The mPC is made to point to the beginning of the target subroutine. m-code is executed until "JSR MBN" is encountered. As this executes, mPC pointing to the first MBC, in this example, blurp, is saved on the machine stack.
The first thing MBN does is grab that return address off the stack, and sets its MBPC to that address. The value that the MBPC had just before, is saved by being placed on the machine return stack, where the return address from the caller had been. In other words, swap [SP] <-> MBPC. Now MBN enters its main loop of looking up addresses and calling subroutines corresponding to Monobyte Codes.
Eventually, MBN execution reaches read-m which tells MBN to get out of its loop. Again we swap swap [SP] <-> MBPC so that on top of the return stack we have the address of the machine opcode INC, and the MBPC is restored to whatever it was before the JSR MBN was encountered - probably for some point of execution in a higher-level caller written in MBC. Because the MBPC was being incremented while executing MBC, it's pointing at the first machine byte following the read-m code.
Eventually, when the machine code is done, a RET is executed, causing machine exectution to return to the caller of this hybrid subroutine.
This is simplest to understand if the procedure for handling read-m is simply a part of the MBN, but in practice the read-m handler is itself a subroutine, just like dup and everything else. Subrountines which play with the return stack and alter teh flow of control can be confusing. I hope my explanation above keeps confusion to a minumum.
From this it appears the Z80 is much better than the 6502, for the Z80 has swap instructions while the 6502 must swap via a third register and use many instructions. Also the Z80 has plenty of on-board 16-bit registers so that one may be reserved as the MBPC, which is faster than the 6502which has even more index registers but are off-board [thinking of page zero memory as 128 16-bit registers]. The 6800 is of unknown virute. It cannot swap like the Z80,it has only one index pointer, but it can handle 16 bits at one time. Of course, the latest 16-bit microprocessors can run circles around any of these 8-bit ones.
How are defining subroutines to be associated with MBCs? Two systems have been developed here at Wilson Enterprises [not a real company!]
The Serial Number System was used in Magellan and was very slow. In this system, all the subroutines are strung together in one linked list. If the a Monobyte Code is 0x38, then the MBN count moduless from the beginning of the linked list: one, two, three... until it reaches 0x38. Almost there. MBN has found only the header; it must determine the name length and skip ahead that far to find the execution entry point. If the next Monobyte Code is 0xFF, woe unto the Monobyte Needle and the human waiting for the result of a computation. Of course, the most-often used subroutines would be placed near the start of the list. The sole virtue of this system is that it costs no space in other than the MBN and the modules themselves.
The Director Table (DT) is a table of addresses of the module subroutines. It directs the processor to the appropriate place. MBN works thusly: the MBC is, say, 0x38. Find the 38th entry in the Director Table. It holds 0xFB92. Jump to the subroutine at 0xFB92. If the next MBC is 0xFF, no problem. The DT in its 255th entry says to execute at 0xF411. It's just as quick. So simple, so quick. This was the system used in the very first pre-NCS system, the old very defunct "MGI" project. If a module is removed from the dictionary of all modules, and we wish to close the gap by relocating all the modules above the gap, we merely change entries in the Director Table and every MBC will retain its meaning. In the Serial Number system, some sort of header must be maintained to hold the place of an obsolete module, so that the 200th module remains the 200th module.
In any reasonable system, such as Galaxy, the DT which defines the 256 Monobyte Codes will reside in ROM. IT could be located in RAM, copied from ROM or even be calculated by something like the Serial Number System, to avoid redundancy, but keeping in mind K.I.S.S., we will put the DT in ROM.
How can user-defined words be implemented? By access codes. A special MBC is set aside to mean, "the next MBC should be interpreted using DT-U1". A spearate Director Table, DT-U1, is built in RAM and directs the processor to all the user-defined subroutines. Those primitives that come built-in take only one byte in MBC, while user-defined subroutines take two bytes, so really it's a sort of "DiByte Code". We can have several access codes, each calling up a different user DT. Having several User DTs allows non-interacting multiple programs in one system, maybe even multi-tasking. Various vocabularies may be built and a context controller defined to make complex programming jobs easier. In fact, in Galaxy, MBCs shall be set aside for accessing special mathematical vocabularies. Maybe we'll have a vocabulary of words which help define weird data structures. But this is getting away from Monobyte Code - here it is important only that access codes to alternative DTs exist.
These are just one byte or an alternative vocabulary access code followed by one byte. There is some choice in how to look at the latter. I consider the access code to be a "Fancy Simple" code, with any class of code following it. To keep the following uncluttered, we'll omit further mention of access codes.
These are pretty much like plain simple codes except that there's more involved than reading one byte and calling a subroutine. Still the MBCs aren't complicated; they only have complicated actions. The codes for converting to m-code, which I have represented as read-m above, and the code end could be put in this calss.
There are some NCS words which get compiled into only one byte, and only one subroutine is called, but that subroutine may be written in MBC and do very complex things to the data stack, in which case we call them "fancy" but still "simple" because there is only one MBC with nothing unusual about it in terms of MBC. Examples like this: dup-th (pushes a copy of the Nth item from top), compile (converts NCS source text into MBC) are merely called, do their complex job and return.
These have an analogy in m-code: immediate mode addressing. An imiportant example in MBC is conb, which is followed by one data byte. When the MBN calls the subroutine for conb, that subroutine must fetch that data byte and push it onto the stack.
Here's what happens when con is encountered: MBN reads the code conb. Via the Director Table, it calls the subroutine associated with con. The first action this subroutine takes is to use MBPC to read the data byte following con. MBPC is incremented. The data byte is read, or "back-grabbed" as we say. It is put onto the data stack along with a zero to pad it to a 16-bit value. Then the conb routine returns to MBN.
This is a lot like a "Load Accumulator Immediate" for any microprocessor, with the machine PC in place of the MBPC and the processor's control logic in place of MBN.
One fact to always keep in mind about backgrabbing Monobyte Codes: They make assumptions about who called them. A subroutine such as the above expects to have been called while MBN is executing a series of MBCs. It cannot be called from a machine code sequence and do anything which makes sense.
Backgrabbing is also possible in m-code, as an opcode JSR xxxx followed by some data bytes, the regular m-code. The subroutine xxxx assumes it is called by m-code, so makes use of the return address on the machine stack, adjusts it, and places it back on the stack before the final RET opcode.
This is from some early version of MBC/NCS, details unknown. Click for higher res image.